#AI #LLMs
DSPy is an optimization framework that can automatically enhance prompts and responses from models. Its capabilities are so extensive that I have yet to master every aspect of it. With the recent release of GPT-4o-mini by OpenAI, I am eager to test its performance on MMLU-Pro with DSPy to showcase the magic of this framework.
In this blog, I will demonstrate how to use DSPy's powerful optimizers, BootstrapFewShotWithRandomSearch and BootstrapFewShotWithOptuna, to improve GPT-4o-mini, even though it is the most cost-effective model in the GPT series.
Setup
To use DSPy, please ensure you have your OPENAI_API_KEY ready and install the DSPy package by following these steps:
pip install dspy-ai
import os
os.environ["OPENAI_API_KEY"] = <OPENAI_API_KEY>
With these preparations, you’ll be ready to leverage DSPy’s powerful optimization capabilities.
MMLU-Pro dataset
MMLU-Pro(Wang et al., 2024) is an advanced dataset that builds on the primarily knowledge-based MMLU benchmark. It introduces more complex, reasoning-intensive questions and increases the number of answer choices from four to ten.
The code for loading dataset from HuggingFace:
# load MMLU-Pro dataset
from datasets import load_dataset
import dspy
# Load the dataset
ds = load_dataset('TIGER-Lab/MMLU-Pro')["test"]
# Create dspy.Example objects with combined options in the question
examples = []
for r in ds:
options_str = " ".join([f"({chr(65+i)}) {opt}" for i, opt in enumerate(r["options"])])
question_with_options = f"{r['question']} \n {options_str}"
example = dspy.Example({"question": question_with_options,
"answer": r["answer"]}).with_inputs("question")
examples.append(example)
# Print the number of examples
print(f"There are {len(examples)} examples.")
# Split the dataset into training and validation sets
trainset = examples[0:100]
valset = examples[100:200]
After executing this code, you will see the progress of the dataset download and the total number of datasets.
There are 12032 examples.
For convenience and simplicity, I am not using the entire dataset. Instead, I will use only the first 200 entries for this test.
Now, let's take a look at the dataset.
example = trainset[0]
for k, v in example.items():
print(f"\n{k.upper()}:\n")
print(v)
QUESTION:
Typical advertising regulatory bodies suggest, for example that adverts must not: encourage _________, cause unnecessary ________ or _____, and must not cause _______ offence.
(A) Safe practices, Fear, Jealousy, Trivial (B) Unsafe practices, Distress, Joy, Trivial (C) Safe practices, Wants, Jealousy, Trivial (D) Safe practices, Distress, Fear, Trivial (E) Unsafe practices, Wants, Jealousy, Serious (F) Safe practices, Distress, Jealousy, Serious (G) Safe practices, Wants, Fear, Serious (H) Unsafe practices, Wants, Fear, Trivial (I) Unsafe practices, Distress, Fear, Serious
ANSWER: I
Evaluation Metric
It's time to define the evaluation metric. This metric will determine if the model's responses match the true answers. To achieve this, I created a function to perform this check.
def eval_metric1(example, prediction, trace=None):
question = example.question
true_answer = example.answer
pred = prediction.answer
if pred == true_answer:
return True
# try to match the question
escaped_pred = re.escape(pred)
pattern_from_question = f"\\(([A-Z])\\)\\s*{escaped_pred}"
match_from_question = re.search(pattern_from_question, question)
if match_from_question:
answer_part = match_from_question.group(1)
else:
# if can not match the question, try to match the pred answer
pattern_from_pred = r"\(([A-Z])\)"
match_from_pred = re.search(pattern_from_pred, pred)
if match_from_pred:
answer_part = match_from_pred.group(1)
else:
# match half )
pattern_half_bracket = r"([A-Z])\)"
match_half_bracket = re.search(pattern_half_bracket, pred)
if match_half_bracket:
answer_part = match_half_bracket.group(1)
else:
answer_part = ""
return answer_part == true_answer
Evaluation Pipeline
Now, the evaluation pipeline needs to be set up.
from dspy.evaluate import Evaluate
evaluate1 = Evaluate(devset=valset, metric=eval_metric1, display_progress=True, display_table=20)
CoT module
Actually, DSPy offers many built-in modules. Here, we use CoT because it is an effective and straightforward method to improve model performance.
# Using cot to answer the questions
## Define a COT class
class CoT(dspy.Module):
def __init__(self):
super().__init__()
self.prog = dspy.ChainOfThought("question -> answer")
def forward(self, question):
return self.prog(question=question)
cot_qa = CoT()
Evaluation
After setting up the module, evaluation pipeline, and evaluation metric, we can proceed with the evaluation to see how the model performs on the test set.
evaluate1(cot_qa)
It will output the final metric for the model's responses. For simplicity, I will not display the detailed output table of the evaluation, only the final result.
Average Metric: 66 / 100 (66.0): 100%|██████████| 100/100 [05:48<00:00, 3.48s/it]
Optimization & Evaluation
There are many optimization methods to choose from in DSPy. To compare their differences, I have selected BootstrapFewShotWithRandomSearch, and BootstrapFewShotWithOptuna.
BootstrapFewShotWithRandomSearch
from tqdm import tqdm
from dspy.teleprompt import BootstrapFewShotWithRandomSearch
tqdm._instances.clear()
config = dict(max_bootstrapped_demos=4, max_labeled_demos=4, num_candidate_programs=10, num_threads=4)
teleprompter = BootstrapFewShotWithRandomSearch(metric=eval_metric1, **config)
optimized_cot_qa = teleprompter.compile(cot_qa, trainset=trainset, valset=valset)
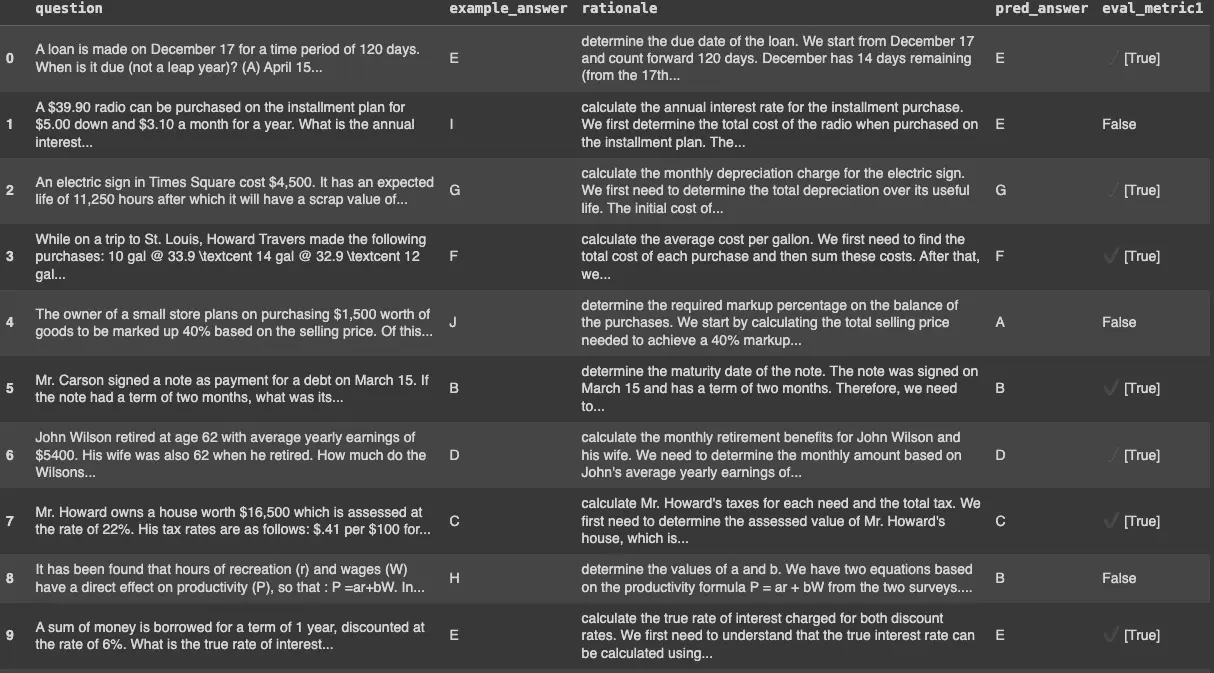
For simplicity, the output for this code is shown in [[#A.]]. There are some important hyperparameters to note in this method:
max_labeled_demos: the number of demonstrations randomly selected from the train set.max_bootstrapped_demos: the number of additional examples generated by the teacher model.num_candidate_programs: the number of random programs evaluated during the optimization.
Now, we can evaluate the optimized model to determine if the accuracy has improved.
Average Metric: 75 / 100 (75.0): 100%|██████████| 100/100 [00:00<00:00, 300.07it/s]
The details of the evaluation for the optimized model are in [[#B]]. It is evident that there is a significant improvement in the model's response accuracy, increasing from 0.66 to 0.75.
BootstrapFewShotWithOptuna
This method is very similar to BootstrapFewShot. It applies BootstrapFewShot with Optuna optimization across demonstration sets, running trials to maximize evaluation metrics and selecting the best demonstrations.
from dspy.teleprompt import BootstrapFewShotWithOptuna
fewshot_optuna_optimizer = BootstrapFewShotWithOptuna(metric=eval_metric1, max_bootstrapped_demos=4, num_candidate_programs=10, num_threads=4)
optimized_cot_qa_optuna= fewshot_optuna_optimizer.compile(student=cot_qa, trainset=trainset, valset=valset,max_demos=4)
Now, let's evaluate the optimized_cot_qa_optuna model to see its performance.
Average Metric: 69 / 100 (69.0): 100%|██████████| 100/100 [00:00<00:00, 363.36it/s]
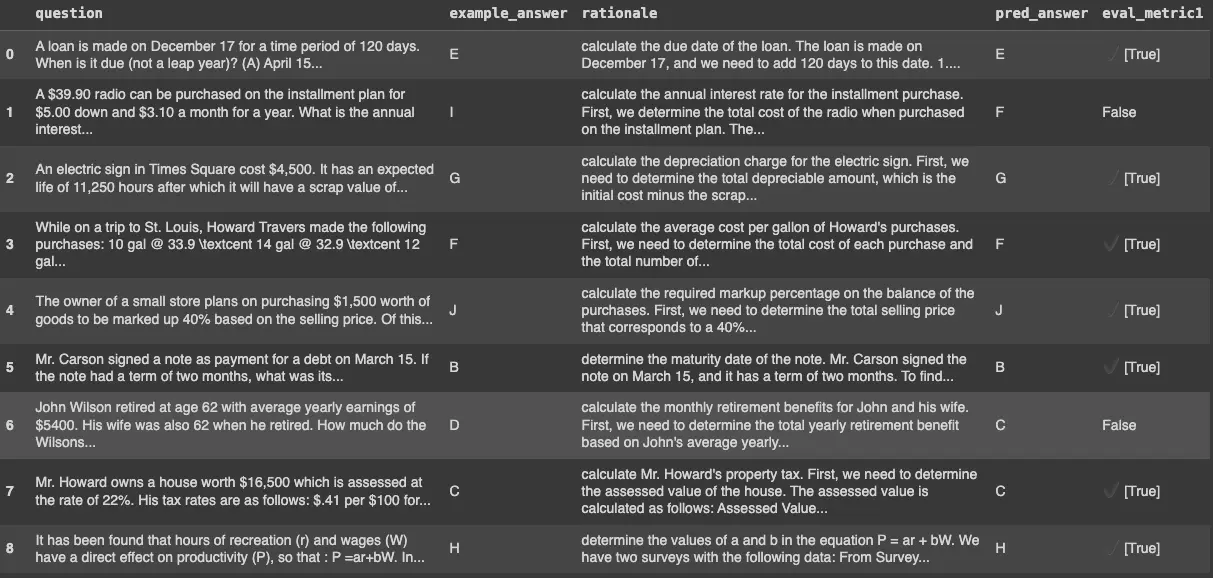
The details of the evaluation for this optimized model are in [[#C]]. As we can see, the accuracy also improved from 0.66 to 0.69, although it is still lower than the BootstrapFewShotWithRandomSearch method.
Conclusion
In this blog, I demonstrated how to use DSPy with GPT-4o-mini on custom datasets. The results show that DSPy can significantly enhance the model's performance. According to the latest release, GPT-4o-mini achieved an overall score of 63.09 without DSPy. However, with DSPy, it reached an overall score of 75, even though I tested only 100 questions.
This blog is not intended to compare the optimization methods in DSPy to determine which is the best. Instead, it aims to show you how to use them. If you're unsure which method to start with, I recommend trying BootstrapFewShotWithRandomSearch first. It is a powerful tool.
Appendix
A.
Going to sample between 1 and 4 traces per predictor.
Will attempt to bootstrap 10 candidate sets.
Average Metric: 66 / 100 (66.0): 100%|██████████| 100/100 [00:00<00:00, 397.79it/s]
Score: 66.0 for set: [0]
New best sscore: 66.0 for seed -3
Scores so far: [66.0]
Best score: 66.0
Average Metric: 68 / 100 (68.0): 100%|██████████| 100/100 [01:10<00:00, 1.43it/s]
Score: 68.0 for set: [4]
New best score: 68.0 for seed -2
Scores so far: [66.0, 68.0]
Best score: 68.0
7%|▋ | 7/100 [00:14<03:08, 2.03s/it]
Bootstrapped 4 full traces after 8 examples in round 0.
Average Metric: 69 / 100 (69.0): 100%|██████████| 100/100 [01:44<00:00, 1.04s/it]
Score: 69.0 for set: [4]
New best sscore: 69.0 for seed -1
Scores so far: [66.0, 68.0, 69.0]
Best score: 69.0
Average of max per entry across top 1 scores: 0.69
Average of max per entry across top 2 scores: 0.77
Average of max per entry across top 3 scores: 0.8
Average of max per entry across top 5 scores: 0.8
Average of max per entry across top 8 scores: 0.8
Average of max per entry across top 9999 scores: 0.8
5%|▌ | 5/100 [00:19<06:04, 3.83s/it]
Bootstrapped 4 full traces after 6 examples in round 0.
Average Metric: 75 / 100 (75.0): 100%|██████████| 100/100 [01:39<00:00, 1.00it/s]
Score: 75.0 for set: [4]
New best sscore: 75.0 for seed 0
Scores so far: [66.0, 68.0, 69.0, 75.0]
Best score: 75.0
Average of max per entry across top 1 scores: 0.75
Average of max per entry across top 2 scores: 0.78
Average of max per entry across top 3 scores: 0.79
Average of max per entry across top 5 scores: 0.81
Average of max per entry across top 8 scores: 0.81
Average of max per entry across top 9999 scores: 0.81
2%|▏ | 2/100 [00:02<02:14, 1.37s/it]
Bootstrapped 2 full traces after 3 examples in round 0.
Average Metric: 67 / 100 (67.0): 100%|██████████| 100/100 [01:21<00:00, 1.23it/s]
Score: 67.0 for set: [4]
Scores so far: [66.0, 68.0, 69.0, 75.0, 67.0]
Best score: 75.0
Average of max per entry across top 1 scores: 0.75
Average of max per entry across top 2 scores: 0.78
Average of max per entry across top 3 scores: 0.79
Average of max per entry across top 5 scores: 0.82
Average of max per entry across top 8 scores: 0.82
Average of max per entry across top 9999 scores: 0.82
1%| | 1/100 [00:02<03:34, 2.17s/it]
Bootstrapped 1 full traces after 2 examples in round 0.
Average Metric: 69 / 100 (69.0): 100%|██████████| 100/100 [01:37<00:00, 1.03it/s]
Score: 69.0 for set: [4]
Scores so far: [66.0, 68.0, 69.0, 75.0, 67.0, 69.0]
Best score: 75.0
Average of max per entry across top 1 scores: 0.75
Average of max per entry across top 2 scores: 0.78
Average of max per entry across top 3 scores: 0.78
Average of max per entry across top 5 scores: 0.8
Average of max per entry across top 8 scores: 0.82
Average of max per entry across top 9999 scores: 0.82
4%|▍ | 4/100 [00:16<06:25, 4.02s/it]
Bootstrapped 2 full traces after 5 examples in round 0.
Average Metric: 71 / 100 (71.0): 100%|██████████| 100/100 [01:21<00:00, 1.23it/s]
Score: 71.0 for set: [4]
Scores so far: [66.0, 68.0, 69.0, 75.0, 67.0, 69.0, 71.0]
Best score: 75.0
Average of max per entry across top 1 scores: 0.75
Average of max per entry across top 2 scores: 0.78
Average of max per entry across top 3 scores: 0.78
Average of max per entry across top 5 scores: 0.79
Average of max per entry across top 8 scores: 0.82
Average of max per entry across top 9999 scores: 0.82
2%|▏ | 2/100 [00:03<03:01, 1.85s/it]
Bootstrapped 2 full traces after 3 examples in round 0.
Average Metric: 74 / 100 (74.0): 100%|██████████| 100/100 [01:21<00:00, 1.23it/s]
Score: 74.0 for set: [4]
Scores so far: [66.0, 68.0, 69.0, 75.0, 67.0, 69.0, 71.0, 74.0]
Best score: 75.0
Average of max per entry across top 1 scores: 0.75
Average of max per entry across top 2 scores: 0.79
Average of max per entry across top 3 scores: 0.8
Average of max per entry across top 5 scores: 0.8
Average of max per entry across top 8 scores: 0.84
Average of max per entry across top 9999 scores: 0.84
8%|▊ | 8/100 [00:24<04:45, 3.10s/it]
Bootstrapped 3 full traces after 9 examples in round 0.
Average Metric: 70 / 100 (70.0): 100%|██████████| 100/100 [01:25<00:00, 1.17it/s]
Score: 70.0 for set: [4]
Scores so far: [66.0, 68.0, 69.0, 75.0, 67.0, 69.0, 71.0, 74.0, 70.0]
Best score: 75.0
Average of max per entry across top 1 scores: 0.75
Average of max per entry across top 2 scores: 0.79
Average of max per entry across top 3 scores: 0.8
Average of max per entry across top 5 scores: 0.81
Average of max per entry across top 8 scores: 0.83
Average of max per entry across top 9999 scores: 0.84
1%| | 1/100 [00:02<03:18, 2.00s/it]
Bootstrapped 1 full traces after 2 examples in round 0.
Average Metric: 66 / 100 (66.0): 100%|██████████| 100/100 [01:09<00:00, 1.43it/s]
Score: 66.0 for set: [4]
Scores so far: [66.0, 68.0, 69.0, 75.0, 67.0, 69.0, 71.0, 74.0, 70.0, 66.0]
Best score: 75.0
Average of max per entry across top 1 scores: 0.75
Average of max per entry across top 2 scores: 0.79
Average of max per entry across top 3 scores: 0.8
Average of max per entry across top 5 scores: 0.81
Average of max per entry across top 8 scores: 0.83
Average of max per entry across top 9999 scores: 0.84
5%|▌ | 5/100 [00:17<05:36, 3.54s/it]
Bootstrapped 3 full traces after 6 examples in round 0.
Average Metric: 70 / 100 (70.0): 100%|██████████| 100/100 [01:51<00:00, 1.11s/it]
Score: 70.0 for set: [4]
Scores so far: [66.0, 68.0, 69.0, 75.0, 67.0, 69.0, 71.0, 74.0, 70.0, 66.0, 70.0]
Best score: 75.0
Average of max per entry across top 1 scores: 0.75
Average of max per entry across top 2 scores: 0.79
Average of max per entry across top 3 scores: 0.8
Average of max per entry across top 5 scores: 0.81
Average of max per entry across top 8 scores: 0.82
Average of max per entry across top 9999 scores: 0.84
2%|▏ | 2/100 [00:04<03:22, 2.06s/it]
Bootstrapped 2 full traces after 3 examples in round 0.
Average Metric: 66 / 100 (66.0): 100%|██████████| 100/100 [01:24<00:00, 1.18it/s]
Score: 66.0 for set: [4]
Scores so far: [66.0, 68.0, 69.0, 75.0, 67.0, 69.0, 71.0, 74.0, 70.0, 66.0, 70.0, 66.0]
Best score: 75.0
Average of max per entry across top 1 scores: 0.75
Average of max per entry across top 2 scores: 0.79
Average of max per entry across top 3 scores: 0.8
Average of max per entry across top 5 scores: 0.81
Average of max per entry across top 8 scores: 0.82
Average of max per entry across top 9999 scores: 0.84
5%|▌ | 5/100 [00:12<03:49, 2.42s/it]
Bootstrapped 4 full traces after 6 examples in round 0.
Average Metric: 73 / 100 (73.0): 100%|██████████| 100/100 [01:26<00:00, 1.16it/s]
Score: 73.0 for set: [4]
Scores so far: [66.0, 68.0, 69.0, 75.0, 67.0, 69.0, 71.0, 74.0, 70.0, 66.0, 70.0, 66.0, 73.0]
Best score: 75.0
Average of max per entry across top 1 scores: 0.75
Average of max per entry across top 2 scores: 0.79
Average of max per entry across top 3 scores: 0.81
Average of max per entry across top 5 scores: 0.82
Average of max per entry across top 8 scores: 0.82
Average of max per entry across top 9999 scores: 0.85
13 candidate programs found.
B
C