
封面提示词:diffraction --ar 16:9 --style raw --p --stylize 1000 💎查看更多风格和提示词
上周精选 ✦
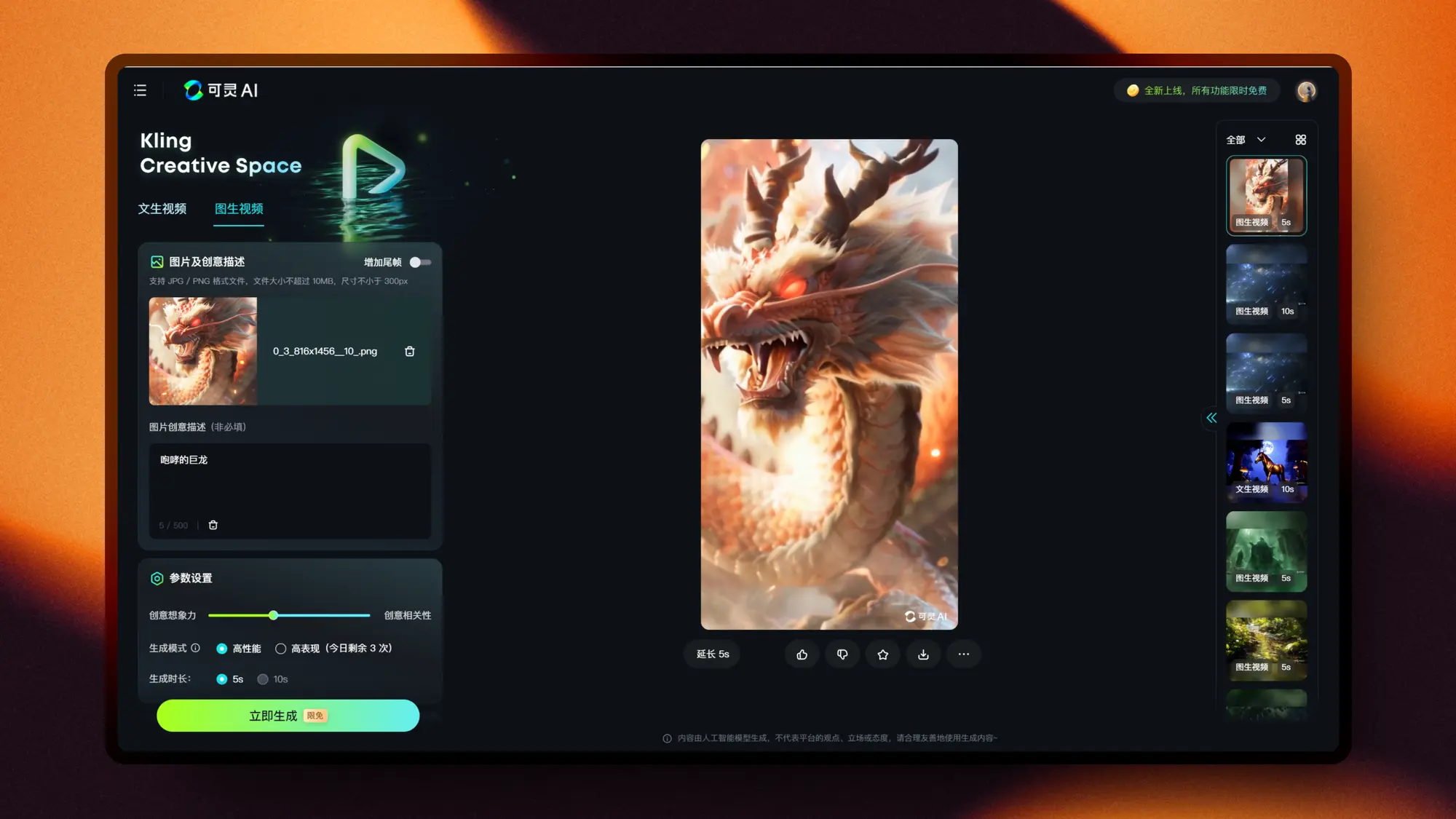
快手发布可灵网页版及大量模型更新
上周的WAIC看了一圈最大的一个内容就是快手可灵的更新了,在第一版模型刚推出一个月之后就提供了升级版的模型,同时快速上线了网页版,这个效率非常不快手。
基础模型更新,新模型输出分辨率为720P,模型的美观度一致性以及运动幅度都有一定的提高,与Runway相差不多了,再结合全面的控制方式的加入,可灵确实是现在最强的视频生成模型了。
每个赛道上最强模型的概念以及认知是必须要争取的,一旦建立这个认知品牌后续的推广和增长都会顺利很多,目前看来可灵很有希望站住视频生成这个赛道。
其他的项目更新有:
- 支持设置视频的创意幅度,幅度越高与原图片或者提示词相差越多
- 支持运镜控制,普通运镜支持控制运镜幅度,大师运镜幅度是自动的
- 增加反向提示词的输入
- 图生视频支持首尾帧控制
- 文生视频支持单次生成10秒长度的视频
新版可灵的效果推荐看坤导的《山海奇镜》预告,我的快速测试在这里,以及如何快速获得首尾帧图片。
可灵模型目前是限时免费的,新模型也就是高表现模式每天三次。
WAIC 信息集合
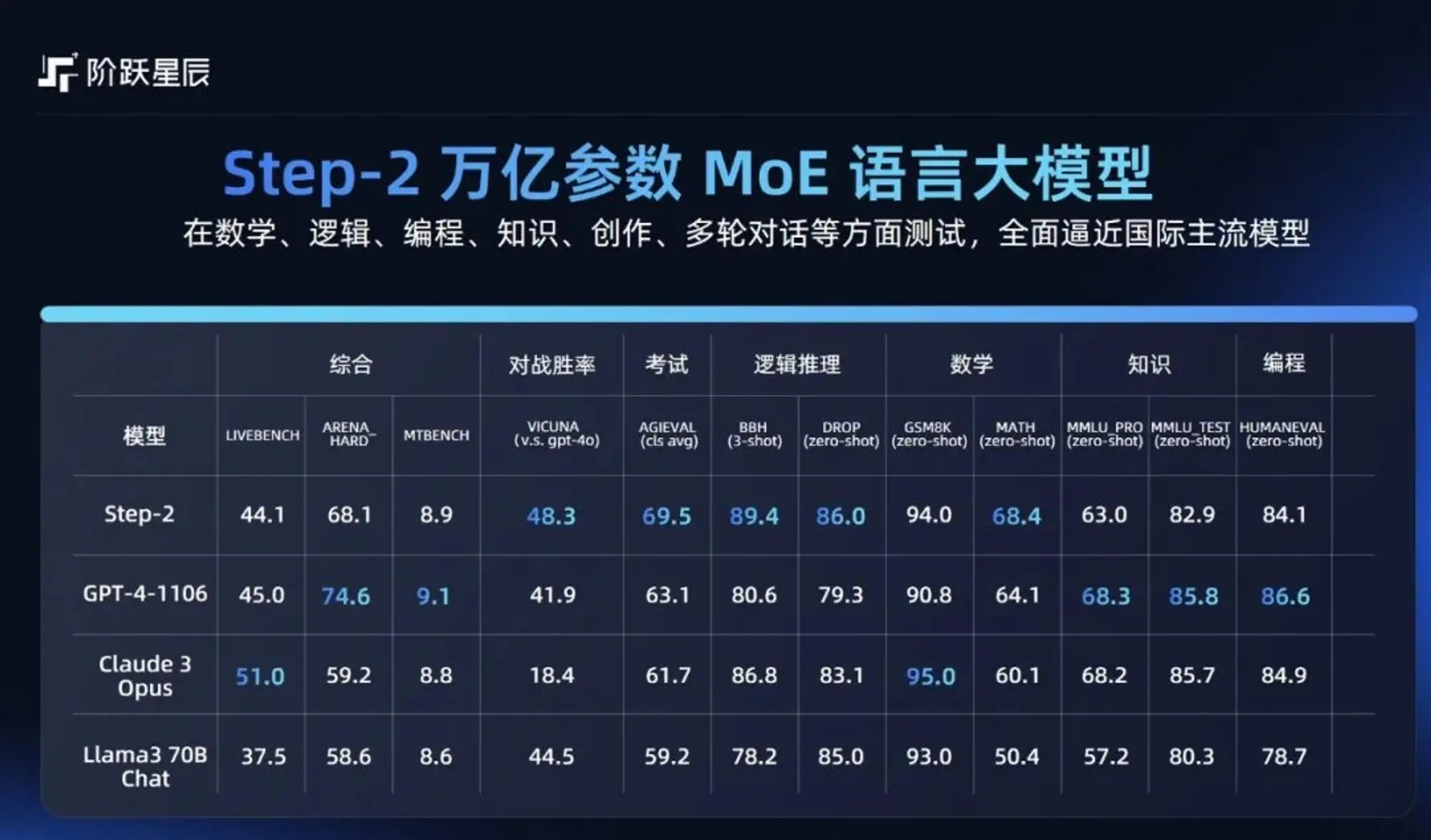
阶跃星辰发布多款模型
阶跃星辰在 WAIC 上发布了三个模型,主打的多模态能力。
Step-2:万亿参数的 MoE 模型,目前还需要申请才能体验,批准的挺快的,不过开放平台过于简陋连一个playground都没有,想体验只能自己调用。
Step-1.5V:千亿参数多模态模型,除了图片理解能力提升外,也支持视频理解。
Step-1X:图像生成模型,DiT 架构,600M、2B、8B 三种不同的参数量,对中国文化和元素进行了优化。
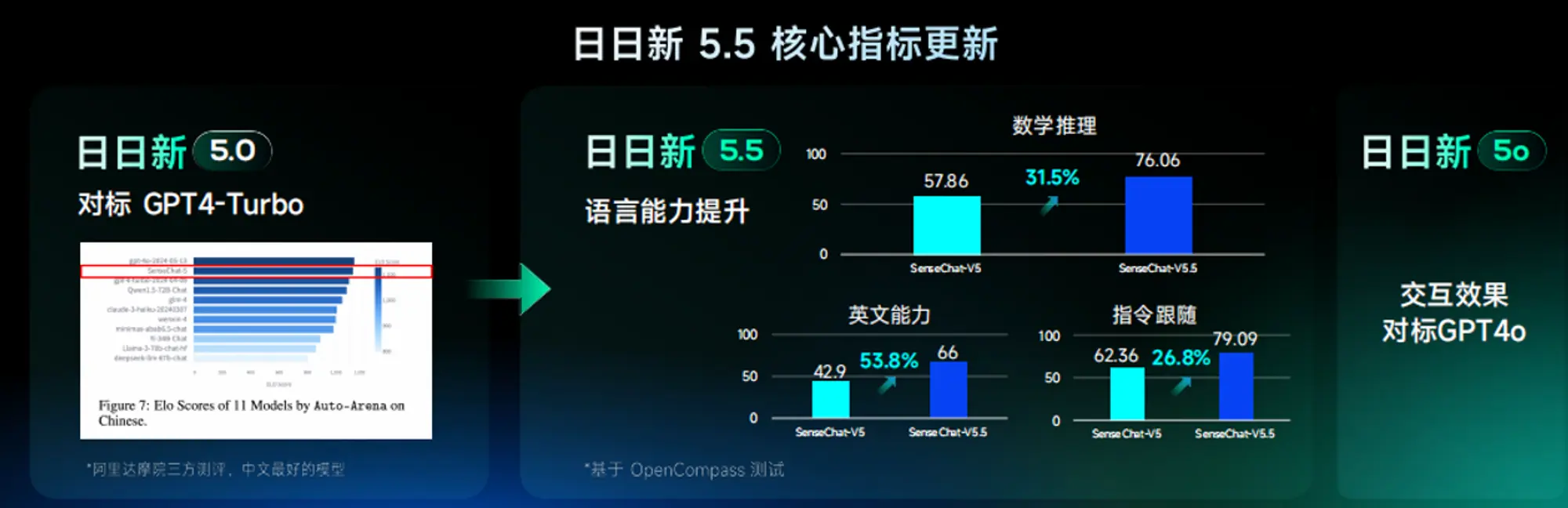
商汤打造类似GPT-4o的实时语音演示
商汤发布“日日新 SenseNova 5.5”模型系列,而且还有类似GPT-4o的日日新5o这名字起的实在离谱。在现场也演示了实时的语音对话演示,还是没有GPT-4o那么流畅,有点回合制的感觉不过也很好了。
模型训练基于超过 10TB tokens 高质量训练数据,包括大量高质量的人工合成数据,构建了高阶思维链。模型采用混合端云协同架构,拥有 6000 亿参数,可最大限度发挥云边端协同,达到 109.5 字 / 秒的推理速度。
他们还发布了一个可以让一张照片直接动起来的小程序Vimi,包括了肢体动作、面部表情加上声音都能控制,小程序目前还在内测。
其他值得注意的信息
- 百度文心智能体平台(AgentBuilder)免费开放了文心大模型 4.0。开发者在文心智能体平台上制作智能体时,可灵活选择文心大模型 3.5 或 4.0 版本,还有李彦宏再出名句“开源模型是智商税”。
- 腾讯混元 DiT 模型升级:推出小显存版本与 Kohya 训练界面,并升级至 1.2 版本,进一步降低使用门槛的同时提升图片质量。
- 智谱 AI 发布并开源代码生成模型 CodeGeeX4-ALL-9B,集代码补全和生成、代码问答、代码解释器、工具调用、联网搜索、项目级代码问答等所有能力于一体。
- 阿里达摩院推出了一站式 AI 视频创作平台 —— 寻光。集成了剧本创作、分镜设计、视频素材编辑等关键步骤,创作者可以从构思到成品,在该平台上完成视频创作全过程。
GraphRAG:微软开源新型RAG架构
在社区摘要应用中,GraphRAG 在全面性和多样性上以 70-80% 的胜率大幅领先于传统 RAG。
GraphRAG 是一种基于图的 RAG 工具,通过 LLM 从文档集合中自动提取丰富的知识图谱,助力处理私有或未知数据集的问答。
GraphRAG 能通过检测图中的“社区”(即密集连接的节点群组),从高层主题到低层话题,层次化地划分数据的语义结构。
它利用 LLM 为这些社区生成摘要,提供对数据集的全面概览,无需事先设定问题。这种方法尤其适合回答全局性问题。

其他动态 ✦
- kyutai这家法国公司小团队也宣布复刻了GPT-4o的实时语音能力,但是模型比较差语速过快,基本不可用,可以借鉴一下思路。
- Fish Speech V1.2 一个还不错的TTS模型,经过 30 万小时的英语、中文和日语音频数据训练。
- Perplexity 发布升级版的专业搜索,提供更复杂的问题解决能力,支持多步搜索和代码能力增强。
- Gorq 现在已经支持 Whisper v3 的语言转文字推理,速度巨快。
- Runway Gen-3模型已经向所有用户开放,一秒视频10积分,价格相当贵。
- Stability AI在获得了新的投资输血,同时换了新的CEO之后可能缓过来了放宽了SD3模型的使用许可,同时宣布会有改善版本的SD3模型开源。
- Cloudflare 发布新工具可以通过单击来阻止 AI 机器人、爬虫和网络爬虫。
产品推荐 ✦
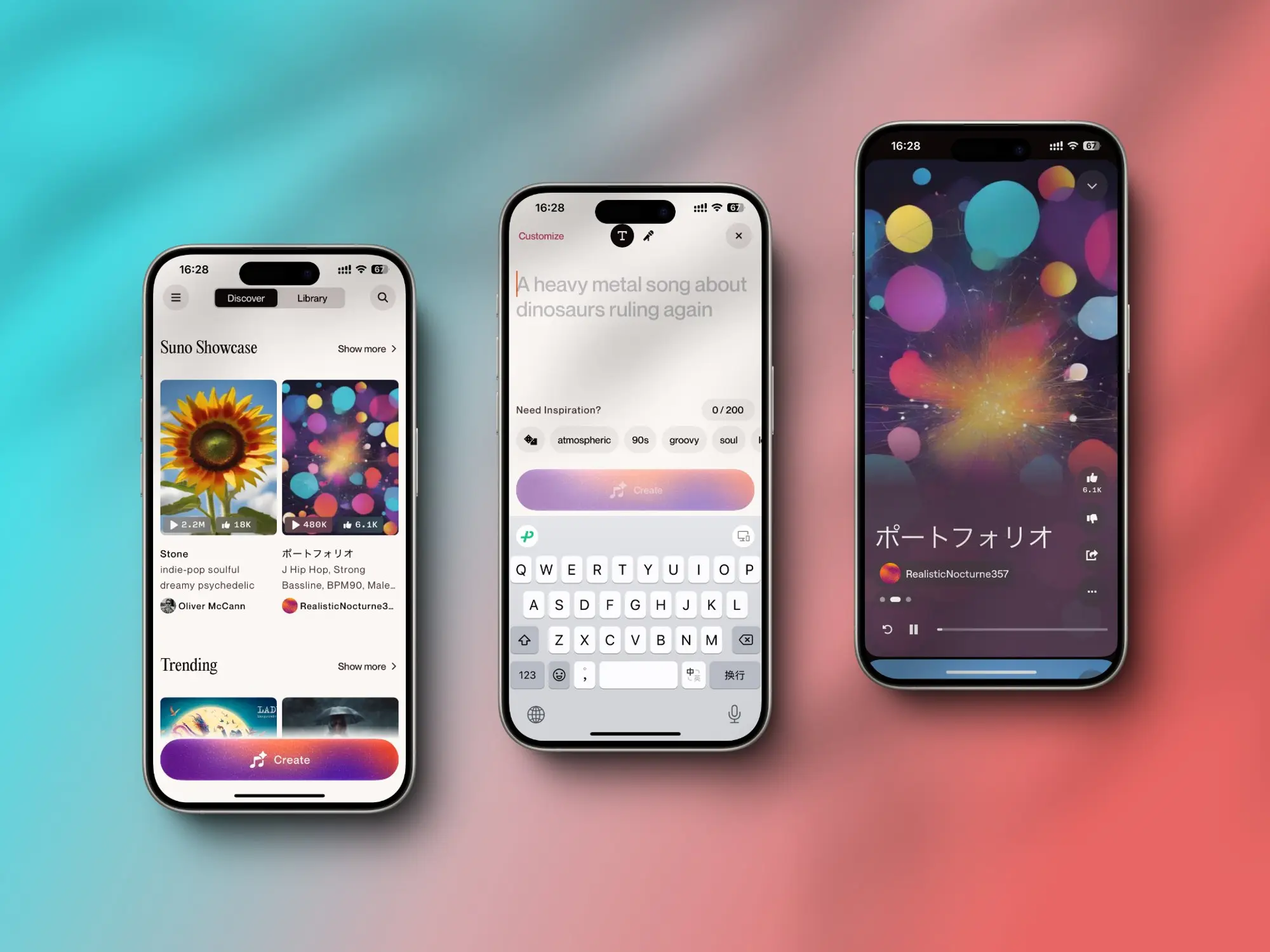
Suno:iOS客户端
Suno 推出了 iOS 客户端,终于可以在手机上收听和创建音乐了。
支持音乐创建和播放功能,播放界面类似信息流,还可以自己创建播单。
目前需要美区 App Store 账号才能下载,下载的时候注意下图标和界面,山寨的应用很多。
Rakis:P2P LLM去中心化推理
Rakis 一个完全在浏览器中运行的P2P LLM推理网络。
在点对点网络上分配和执行人工智能推理任务,无需依赖集中式服务器。
可以选择对应的模型发送内容到其他节点推理,同时也会接受其他节点的推理任务。
挂机帮助推理可以获得Token,目前节点还不多。
这个的优势主要是门槛低,打开就能工作,不过估计是为了照顾低显存用户,最大的模型就Llama3 8B。
Kimi 浏览器扩展
KImi推出了自己的官方浏览器扩展,支持划线询问kimi相关内容,也可以直接总结页面内容和追问。
ElevenLabs AI语音降噪
AI 语音隔离器增强音频并净化人声。只需上传文件即可消除街道噪音、麦克风反馈和任何其他不必要的背景噪音。
Screen:个人设备助理
全天记录你的屏幕信息和麦克风信息,并将其连接到LLMs。受 adept.ai , rewind.ai , Apple Shortcut 的启发。用 Rust 编写。免费。数据都在本地保存。
screenpipe 是一个库,允许收集所有生活背景并将其轻松连接到LLMs。
- 搜索(例如,超越有限的人类记忆)
- 自动化(例如在工作时在网络上执行操作,同步公司的知识等)
精选文章 ✦
理解深度学习
麻省理工这本《理解深度学习》的免费书可太好了。深入讲解了深度学习的大部分概念。而且每个章节都有搭配的PPT可以下载,还有对应练习的Python代码。
内容包括监督学习、神经网络、损失函数、正则化、卷积网络、Transformers、扩散模型、强化学习等。页面上还有更多分支的学习路径和资源。
类似的学习资料还有李沐的这本《动手学深度学习》。
[指南] AnimateDiff/Hotshot 的反采样
Inner-Reflections 发了一个使用反向采样优化 Vid2Vid 效果的教程。只使用了一个 ControlNet 的情况下转绘的效果就有了很大的提升。提供了详细的工作流讲解和文件。
高盛报告:Gen AI:花费过多,收益太少?
生成式人工智能技术承诺改变公司、行业和社会,这导致科技巨头及其他公司预计未来几年将花费约 1 万亿美元在资本支出上,包括大量投资于数据中心、芯片、其他人工智能基础设施和电网。
但迄今为止,这些支出所取得的成果甚微。这种大规模支出是否会在人工智能效益和回报方面得到回报,以及如果得到回报对经济、公司和市场的影响,或者如果没有得到回报的影响,都是当前最关注的问题。
构建人工智能产品的反直觉建议
文章详细探讨了来自多位资深产品构建者的建议,他们在人工智能领域有着丰富的经验。这些建议挑战了常规思维,强调了在 AI 产品开发中需要注意的一些关键点。
例如,文章指出,最初的产品版本并不需要完美无缺,而是应该尽快推向市场,以便从用户反馈中学习和改进。
此外,产品的成功往往与团队的多样性和对于市场的深刻理解有关,而不仅仅是技术实现本身。
文章还强调,AI 产品的开发应该以解决具体问题为导向,而不是仅仅展示技术的能力。
最后,文章提到,建立良好的人工智能产品需要不断迭代和适应市场的变化,同时也要有耐心和对未来的长远思考。
Let’s Get Agentic:LangChain和LlamaIndex谈论AI Agent
在 2024 年 7 月 2 日举行的 AI 工程师世界博览会上,LangChain 的创始人兼首席执行官哈里森・切斯(Harrison Chase)和 LlamaIndex 的创建者杰里・刘(Jerry Liu)分别就 AI 代理的发展讨论了他们的观点。切斯在他的演讲中提到了 AutoGPT,指出它代表了 AI 代理领域的一次高潮,但随后的跌落表明了通用代理架构的不可靠性。
与此同时,杰里・刘介绍了 LlamaIndex 的 “知识助手” 概念,这是对 AI 代理的重新品牌,旨在使企业更容易理解和接受。他描述了从简单的 RAG 系统到更高级的代理工作流程的演变,并展示了 LlamaIndex 如何支持构建更复杂的代理,包括个性化的问答系统、能够维护用户状态的代理以及能够从结构化和非结构化数据源查找信息的代理。
我如何训练 LoRA:m3lt 风格训练概述
主要介绍了作者 alvdansen 使用 LoRA Ease 工具训练 “m3lt” 风格 LoRA 模型的步骤和经验。
作者认为 LoRA 训练不是通过教程即可快速学会的,而是需要从他人那里学习,因为它需要艺术和图案识别的混合理解。作者建议初学者在尝试 LoRA 之前先使用几个 LoRA 模型,以便在测试自己的模型时能够识别出好的结果。作者还强调,即使是经验丰富的训练者,也可能需要多次重新训练以达到理想的输出。
作者提供了详细的训练参数设置,包括优化器、学习率、训练步数等,并建议在出现过拟合或欠拟合时如何调整这些参数。最后,作者分享了一些训练结果的例子,并对不同提示与独特 token 之间的关系以及如何通过调整标注风格来改善模型表现进行了最终的观察。
渐进,然后突然: 跨越临界点 小进步可能带来大变化
探讨了人工智能(AI)在工作、教育和生活中的应用及其影响。文章强调了技术进步的非线性特征,特别是AI能力在达到特定阈值时的突变,举例说明了AI在图像和视频生成、数据分析等方面的显著进步,并讨论了AI在实际应用中的门槛问题。
- AI在实际应用中的门槛: 尽管AI在生成视频方面取得了进展,但要成为商业上可行的工具,取代专业电影制作人员,还需要跨越更高的门槛。
- 用户体验的小改进与门槛跨越: 通过改善用户体验,即使是小的改动,也能使AI跨越使用门槛,如Claude 3.5 Sonnet的“artifacts”功能。
- AI的隐形门槛: AI能力的提升往往是微妙的,需要通过实践和体验来感知,作者建议保持一个“不可能清单”来跟踪AI的进步。
- AI能力的持续改进: 尽管AI技术的当前浪潮最终可能达到极限,但在那之前,重要的是关注AI能力阈值的变化,而不是单纯的能力提升。
重点研究 ✦
Meta 3D Gen 文本生成3D模型
Meta 发布 Meta 3D Gen 文本生成3D模型。模型质量非常高。而且还自带高分辨率纹理和材质贴图可以在一分钟内生成,是现有方案的3-10倍。支持物理基础渲染(PBR),在应用中用于3D资产的重新照明。
3DGen集成了我们为文本到3D生成和文本到纹理生成开发的两个关键技术组件,Meta 3D AssetGen和Meta 3D TextureGen。
快手开源可图图像生成模型
快手还开源了可图图像生成模型,模型使用了SDXL相同的架构训练,并采用不同的噪声调度程序和 GLM 模型(而非 CLIP)。模型质量和表现很强Playground V2.5,但是提示词理解要强很多,同时支持中文和英文提示词,支持在画面直接生成中文文字。
ControlNeXt:新的图像控制模型
同时支持对图片和视频的控制。与 ControlNet 相比,可减少高达 90%的可训练参数,实现更快的收敛速度和出色的效率。
也可以与其他 Lora 技术结合,改变风格并且稳定控制生成内容。可以用这个 精细控制 SVD 模型的生成。
LivePortrait:快手的面部表情动画迁移项目
面部表情迁移到图片生成视频的技术,控制的非常好。感觉对 AI 视频生成中人物表演和数字人非常有帮助。支持各种风格的图片,同时可以对面部运动幅度进行微调,也支持常见的动物面部迁移。
为了提升生成质量和泛化能力,我们将训练数据扩展至约6900万帧高质量图像,采用图像和视频混合训练策略,升级了网络架构,并设计了更优的动作变换和优化目标。
发现紧凑的隐式关键点可以有效地表示一种混合形状,并精心设计了一个缝合和两个重新定向模块,这些模块利用了一个小型MLP,几乎不增加计算开销,从而增强了可控性。
ComfyUI插件已经有了,ComfyUI-LivePortraitKJ。
稀疏架构大型语言模型的专家专业微调
Deepseek 新论文针对稀疏架构LLM专家特化微调方法。
这篇论文提出了一种名为"专家特化微调"(ESFT)的方法,用于高效地微调具有混合专家(MoE)架构的大语言模型。
主要思路是只微调与特定任务最相关的专家,而冻结其他专家和模块。
这种方法不仅提高了微调效率,在下游任务上达到甚至超越全参数微调的性能。
重要的人工智能智能体
AI Agents That Matter 这篇论文的作者调研过后发现,相当多的 Agent 相关论文不可复现且忽视使用成本。作者提出了几个改进建议:
1)在评估 AI Agents时,不仅要考虑准确性,还要考虑成本。
2)应该同时优化准确性和成本,找到最佳平衡点。同时展示了一种优化方法。
3)要区分对 AI 模型的评估和对实际应用的评估,因为它们的需求是不同的。
4)评估基准需要有合适的测试集,以防止 AI 代理系统钻漏洞或过度拟合。
5)评估方法需要更加标准化,以确保结果可以重复验证。
Mooncake:以 KVCache 为中心的分解LLM 服务架构
月之暗面居然发论文了。介绍了他们的 LLM 推理服务架构。Mooncake的创新架构使得Kimi能够处理更多请求,同时保证服务质量。
Mooncake的核心思想是将LLM推理过程中的prefill(预填充)和decoding(解码)阶段分离,并以KVCache(键值缓存)为中心进行优化。
它充分利用GPU集群中的CPU、内存和SSD资源来实现一个分布式的KVCache系统,从而提高资源利用率和推理效率。
Mooncake还采用了一系列创新策略来应对长上下文和系统过载等挑战,显著提升了LLM服务的性能和吞吐量。
InstantStyle-Plus:图像风格保持
小红书团队发布进阶的风格保持项目InstantStyle-Plus。
在原来 InstantStyle 的基础上增加了两种方法来保持原图的结构:
1)用"反向噪声"来初始化图片生成过程,;
2)用"Tile ControlNet"来控制生成过程。
使用了全局的图像适配器保持语意内容,比如人物的身份、性别、年龄等。
MimicMotion:动作控制图片变视频
腾讯发布了一个根据图片生成跳舞视频的项目MimicMotion。效果看起来比阿里的好很多,同时支持面部特征和唇形同步,不止可以搞跳舞视频,也可以做数字人。
比阿里的方案优化的内容有:
引入基于置信度的姿态引导机制。确保生成的视频在时间上更加连贯流畅。
开发了基于姿态置信度的区域损失放大技术。能够显著减少生成图像中的扭曲和变形。
提出创新的渐进式融合策略。能够在可接受的计算资源消耗下,实现任意长度视频的生成。
FunAudioLLM:用于人类和LLMs之间自然交互的语音理解和生成基础模型
其核心是两个创新模型:SenseVoice 用于高精度多语音识别、情感识别和音频事件检测;CosyVoice 用于具有多语言、音色和情感控制的自然语音生成。
SenseVoice 具有极低的延迟,并支持 50 多种语言,而 CosyVoice 在多语音生成、零样本语音生成、跨语言语音克隆和遵循指令能力方面表现出色。
通过将这些模型与LLMs集成,FunAudioLLM 实现了诸如语音翻译、情感语音聊天、互动播客和富有表现力的有声读物叙述等应用,从而推动了语音交互技术的边界。
多模态 LLM InternLM-XComposer-2.5
AI lab 开源了一个非常强的多模态 LLM InternLM-XComposer-2.5 。支持超高分辨率图像理解、细粒度视频理解、多轮图像对话。另外专门针对网页制作和图文文章混排做了优化。
长上下文处理:IXC-2.5原生支持24K标记的输入,可扩展到96K,能处理超长文本和图像输入。
多样化视觉能力:支持超高分辨率图像理解、细粒度视频理解和多轮多图对话。
其他功能:可以生成网页和高质量文章,结合了文本和图像。
模型架构:包括轻量级视觉编码器、大语言模型和部分LoRA对齐。
测试结果:在28个基准测试中,16项超过开源模型,16项接近或超过GPT-4V和Gemini Pro。
想要玩 Stable Diffusion AI 画图但是没有好的硬件的可以看一下揽睿星舟,
做了很好的适配可以一键部署 SD 价格也很划算。最近还上线了优化的非常好的Comfyui,感兴趣可以试试
https://www.lanrui-ai.com/register?invitation_code=9778
一直有很多朋友跟我说看推特或者微博的时候信息获取效率太低,因为有很多无关的信息,希望我整一个比较垂直的站展示最近的 AI 资讯。
搞了一个 guizang.ai ,感兴趣可以来看看,每天更新最新的 AI 资讯和值得关注的研究内容,我的一些深度内容也会整理后放在这里。
感谢大家看到这里,如果有觉得有意思的相关内容也可以私信我或者给我发邮件投稿。
你可以在这里找到我:
| 即刻 | 推特 | Quail订阅 | 微信公众号:歸藏的AI工具箱 |邮箱:[email protected]
也可以分享给更多的朋友,让大家都有机会了解这些内容。






