
关于本刊
这是猫鱼周刊的第 19 期,本系列每周日更新,主要内容为每周收集内容的分享,同时发布在
博客:阿猫的博客-猫鱼周刊
RSS:猫鱼周刊
邮件订阅:猫鱼周刊
微信公众号:猫兄的和谐号列车
前言
本期周刊的内容大多数是 LLM 相关的,也许最近几期都会是(因为我最近的专注点就在 LLM)。本期主要是从比较基础的概念等去入手,在了解这些概念之后,即使你先前没有 NLP 相关的经验,也能跟别人对 LLM 这个话题侃侃而谈。
文章
什么是 token 以及怎么数它们
来自 OpenAI FAQ 的一篇文章,浅显地介绍了什么是 token,以及 token 的计数方式。简单来说,一个英文单词并不等于一个 token,一个英文单词中的要素等于一个 token,单词在句中不同的位置也会导致它变成另外一个 token(id)。
image.png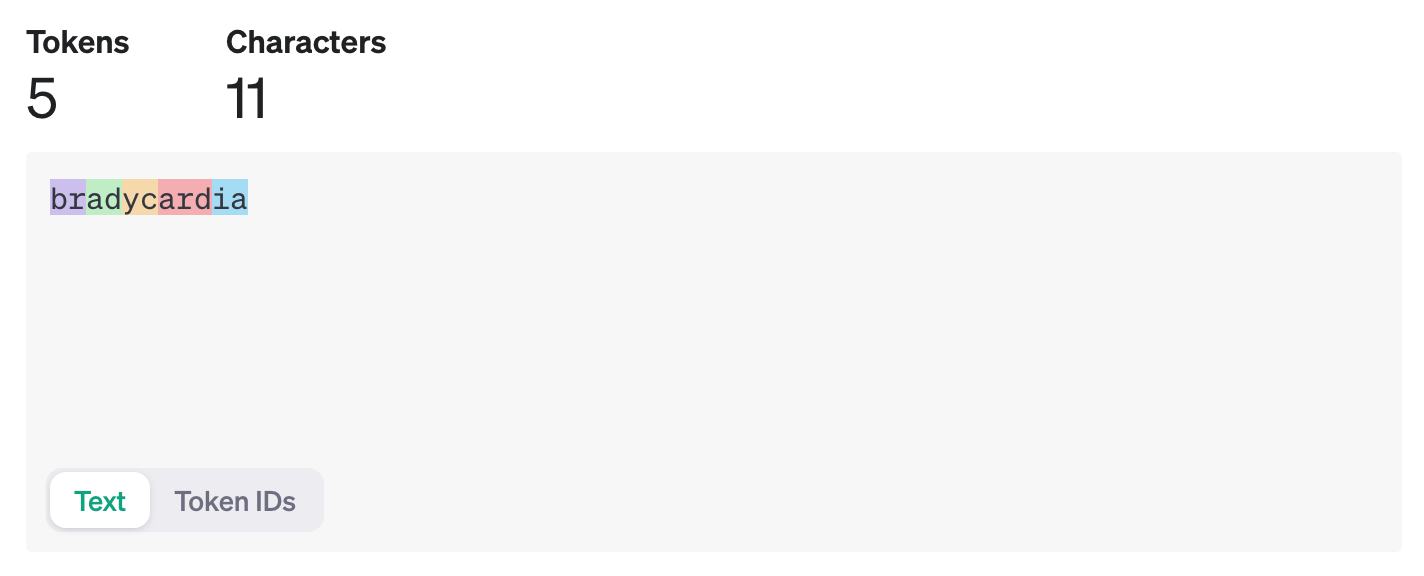
例如 bradycardia 这个单词,就包含了 5 个 token。具体每一个 token 具有什么含义跟我们没什么关系,模型懂就行。
你可以在 OpenAI Platform 找到 OpenAI 提供的这个工具。注意,不同模型使用的 tokenizer 会略有差异,因此这个也只适合 OpenAI 自己的模型。
检索增强生成(RAG)
LLM 的训练语料是有截止时间的(例如 GPT 3.5 的语料截止时间应该是 2021 年 9 月,而 GPT 4 则到 2023 年 4 月左右,见这里),而且对于没有训练过的领域 LLM 也无法正确回答,因此 LLM 需要基于外部知识来解决生成幻觉问题。
当用户提问时 “美国总统是谁?” 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中(如下图中的维基百科)进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第 46 届总统…),然后再将用户问题和搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
RAG 一般来说包含了检索、重排序(rerank)两个过程。
语义搜索入门
近几年 NLP 技术飞速发展,在 embedding 出现以前,搜索基本上是精确搜索(例如 Elastic Search)的天下。在有 embedding 之后,就可以实现语义搜索。例如在谷歌上搜索 slow heart rate ,就会被自动链接到 bradycardia ,这对搜索是一个极大的改进,因为 a) 搜索的人不一定能命中要查询的专业词汇,b) 有时候一个事物会有多种不同表达。
embedding(词嵌入)是一种将语义转化成向量表示的方法,由模型学习获得。将语义向量化后,可将其视为高维空间中的一个点。语义相似度就是求这个点与其他点的距离(如余弦相似度等,有多种算法)。
这篇文章基于 qdrant 实现了一个简单的书籍信息语义搜索,基于书籍的简介,将书籍简介和用户输入都向量化,然后寻找与用户输入相似度最高的几个作为搜索结果。
Grok-1.5
马斯克的公司 xAI 搞的 LLM,对标 GPT 4、Claude 3 Sonnet 的一个模型。比较吸引我的点是,这个似乎不是特别依赖 GPU,使用 CPU 也可以运行。而且他们用的是一个自研的分布式训练框架(基于 JAX,Rust 和 K8s),这个框架会不会开源呢?拭目以待。
另外,比较有趣的是,这个公司的技术团队中,不乏华人。见 About xAI。
国行版 iPhone 阉割了那些功能?
客观地说,“阉割” 一词是不严谨的,苹果的硬件会根据销售地区和使用地区有不同的使用限制,这个做法在很多别的厂商的机器上也会有,属于是合规要求和商业选择。合规要求是指所在地法律法规和政策等限制的,属于厂商没得选的;商业选择是厂商主动放弃在这个地区开展服务,就好比快递公司主动选择不在某片区服务。因此我对国行阉割功能的态度是,不要抱怨苹果或者有关部门,有需要你就找渠道买外版,图省事就买国行。
近期来说,影响比较大的可能有:
- iOS 18 端内 AI 可能会采用百度的模型
- 可能不再允许跨区下载应用,国区未备案的 app 即将下架
项目
babyname/fate

一个现代科学取名工具,根据一些玄学算法起名,不明觉厉。
omriharel/deej

开源硬件音量均衡器。LTT 甚至做了半期视频来讲。
工具/网站
LLM Leaderboard
这周在调研 LLM 的时候,需要考虑到 LLM 的各方面能力,以及成本和上下文长度等。找到了这两个网站。第一个更全面一些,有主流商用和开源的 LLM 在各 benchmark 上的得分,上下文长度,token 价格等。第二个只有 benchmark,但是涵盖了更多开源的模型。
image.png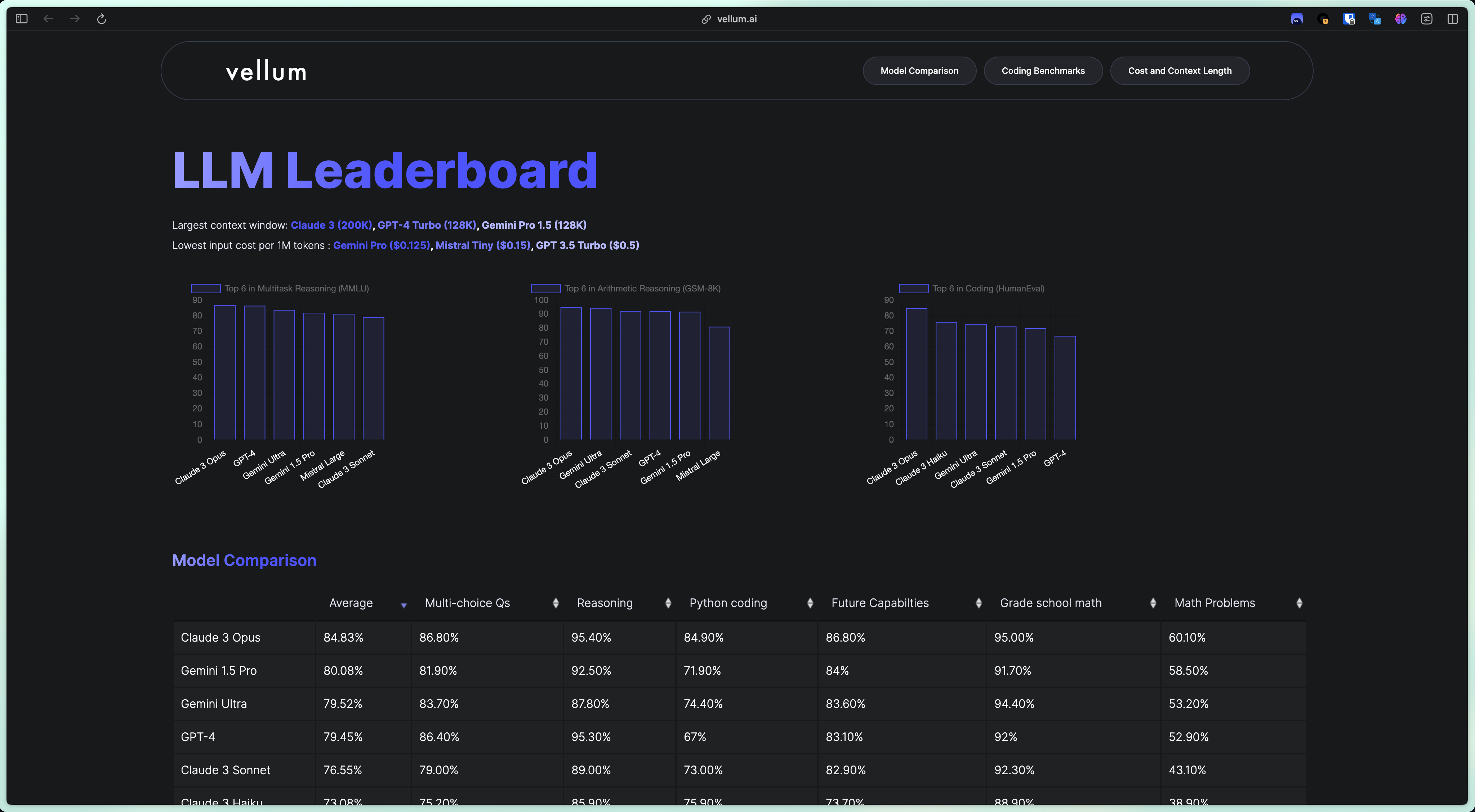
image.png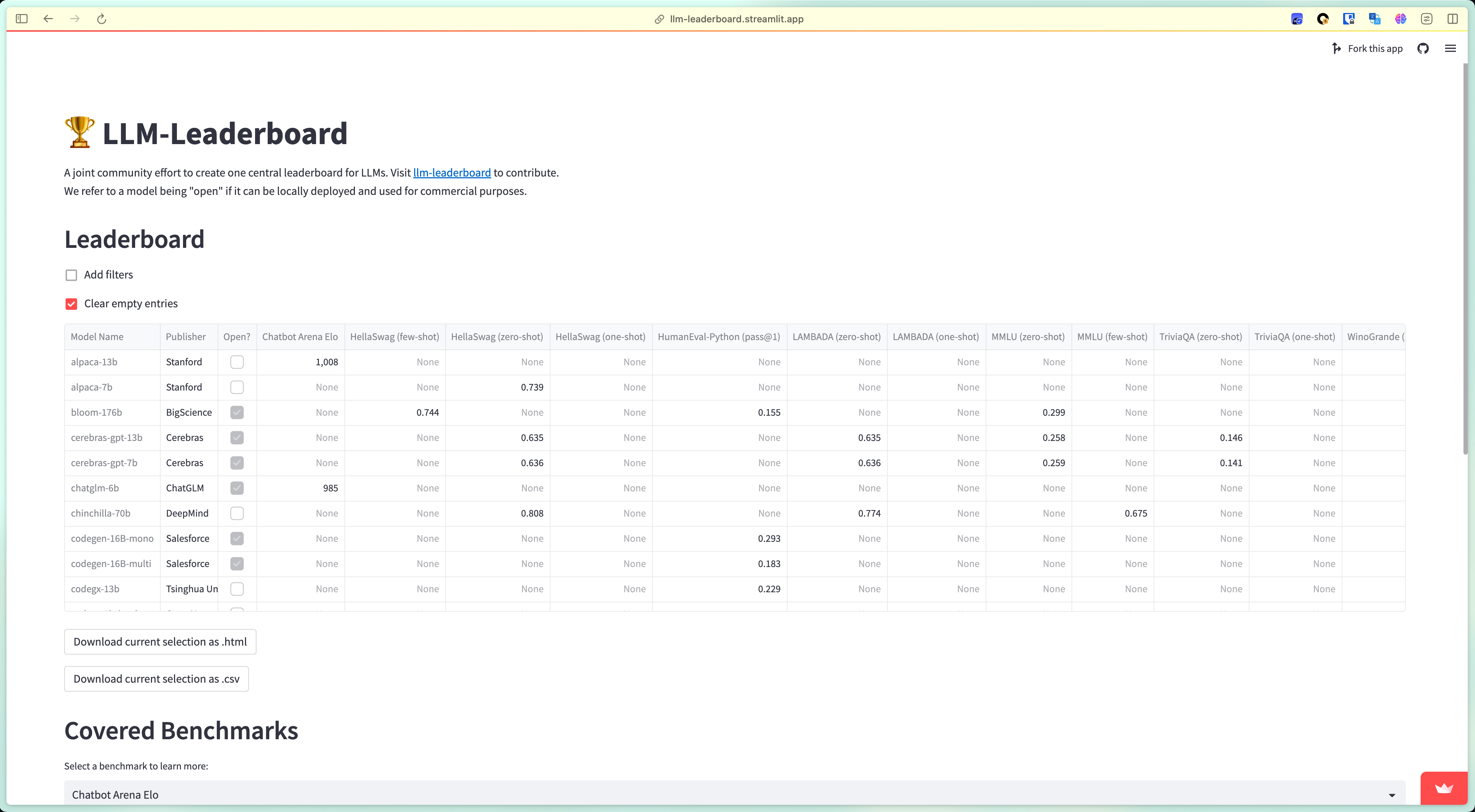
最后
建了一个微信交流群,感兴趣可以进来聊天吹水。
WechatIMG38.jpg






{kind=link}