引言
Google前阵子发布的Gemini 1.5 Pro,是一个具有1M上下文窗口的LLM,它在处理大量信息时表现出色,尤其是在“大海捞针”实验中达到了99.7%的召回率。
在科技的浪潮中,每一项新兴技术都似乎预示着旧技术的终结。然而,当我们观察 RAG 和 long context,一个有趣的现象出现了:被大模型厂商认为即将被淘汰的技术 RAG,却被企业客户视为好用的新技术,其应用非常扎实也越来越广泛。
这种认知上的巨大差异非常有趣,本文将深入探讨RAG与Long Context之间的这场认知冲突,并试图揭示背后的深层次原因。
RAG 技术的价值
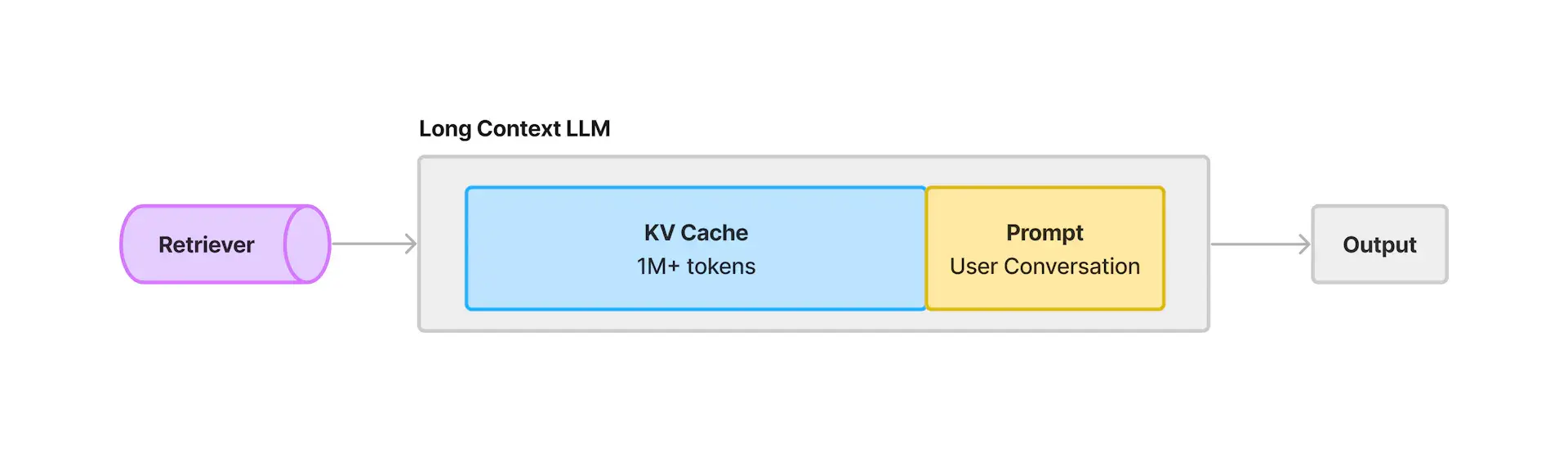
RAG技术是一种结合了信息检索和文本生成的方法。众所周知,LLM的信息来自互联网的公开数据,它并没有企业的垂域私域数据,而RAG技术可以通过把企业的知识库作为插件,从私域数据中检索相关信息,然后将这些信息放到LLM的context中,从而提高LLM具备企业私域知识问答的能力。
但 RAG 并不是完美的技术,企业的数据格式千差万别,需要一定的归一化,才能被很好地检索到。而且被检索到的也只是一些知识的切片,并非整个知识库,所以其产生的回答并不是基于对文本真正理解的基础上,而是对片面的知识的理解。
因此,RAG被一些LLM厂商视为一种过渡性技术,注定要被更先进的Long Context技术所取代。