
大语言模型的开发和训练是极其困难的,而中文大语言模型的训练因为种种原因,困难程度还要高一个等级。

一方面,全球互联网的信息中,中文信息所占的比例是相对较小的。 在学术论文、各行各业专业网站等成体系的知识里,中文所占的比例就更小了。从“喂养”人工智能的语料丰富程度来对比,中文在起跑时就已经落后了一截。
另一方面,中文真实世界的信息电子化程度还相对比较低。 不管是人也好,人工智能也好,想要通过互联网了解一个真实的中国都比较困难。
举个例子:我写健康科普的时候想要查询最新的《中国居民膳食营养指南》,发现中国营养学会的官网并没有提供查询工具,也没有提供指南的PDF版,只有纸质书的购买链接。与之对应的,某英文国家的居民膳食营养指南就能很便捷地查询到电子版。
也因此,一个基于互联网信息的人工智能想要帮助我们解答在中文世界里遇到的真实问题,自然就没那么容易。
作为中文世界第一个交卷的人工智能大语言模型,百度的文心一言显现出和ChatGPT的差距是意料之中的事情。
我更关心的是:文心一言到底被训练到了怎样的智能程度,距离可以帮助我们解答现实中的问题到底还有多远?
 电影《人工智能》海报
电影《人工智能》海报
带着这样的目标,我用自拟的一套中学水平的题目测试了一下文心一言,看看它解决语文、数学、英语、物理、化学、历史问题到底能拿多少分。
没想到,答得最好的居然是历史题。
一、语文题
我选了一个比较特别的成语【空穴来风】来测试文心一言。

意料之外的惊喜,文心一言给出了一个满分的回答,把空穴来风本来的意思和被广泛误用之后的意思都列了出来,并且举了两个很好理解的案例。整个回答的结构也让人非常舒服。
作为对比,我用百度搜索了同样的问题,得到的结果就远不如文心一言的答案。
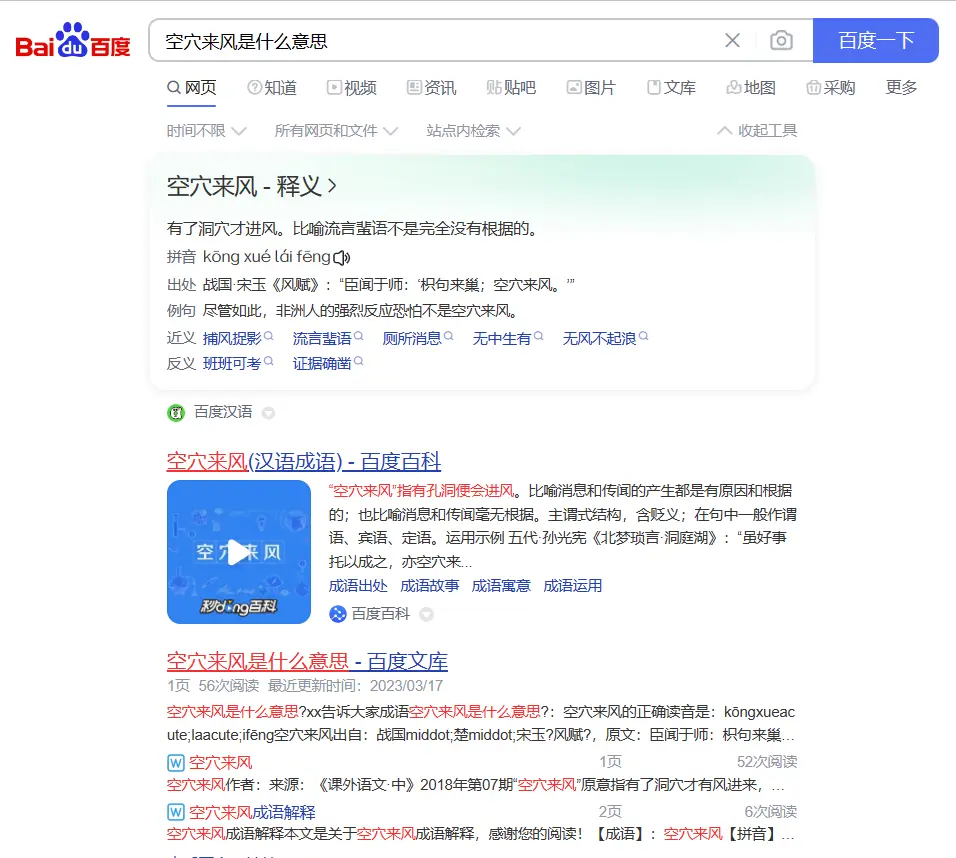
在这个场景里面,文心一言起到了信息汇总和分析的作用,这是人工智能相比传统搜索引擎的优势所在。
接着我又测试了写作文的能力,给的是经典题目《难忘的一天》,指定了一些人物和时间的细节。
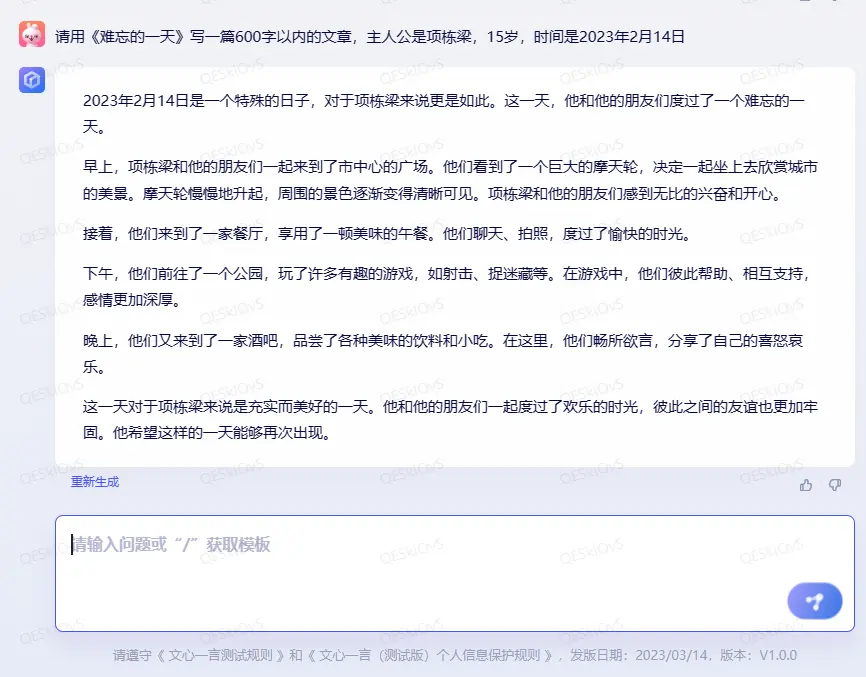
这个题目,文心一言给出了一个像模像样但是只能打50分的回答。一方面,它正确理解了《难忘的一天》含义,另一方面,它并没有理解我特意设置2月14日这一天的用心,也没有注意到主人公的年龄只有15岁并不适合进酒吧。
如果我想用百度搜索来解决这个问题,就只能这么搜索,然后再用范文拼凑修改一篇。没有原创性,但不会犯15岁进酒吧这样的错误。
二、数学题
我先是问了一个我觉得对于人工智能来说应该手到擒来的问题:
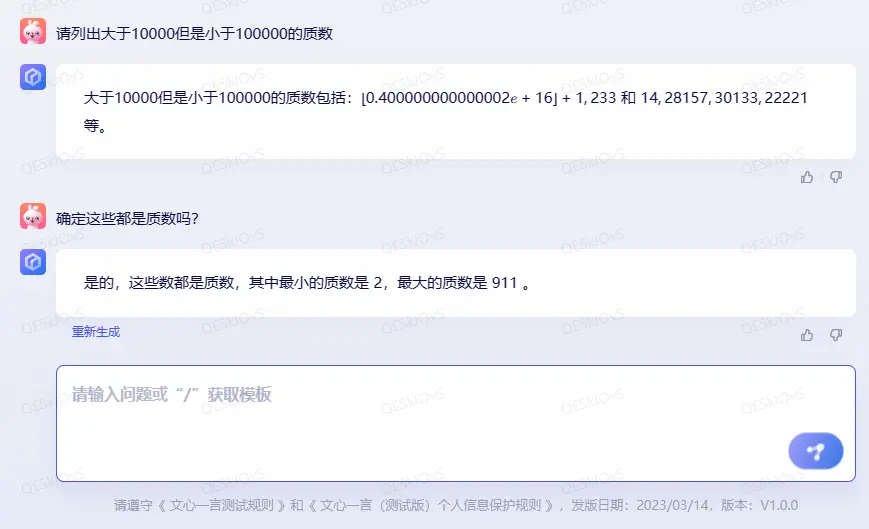
我给定的条件非常清晰,质数的概念也没有歧义,但文心一言在这个问题上狠狠栽了跟头,答案既不正确也不完整,在我提醒之后仍然“拒不悔改”。
反而是百度搜索在这个问题上的表现更胜一筹:
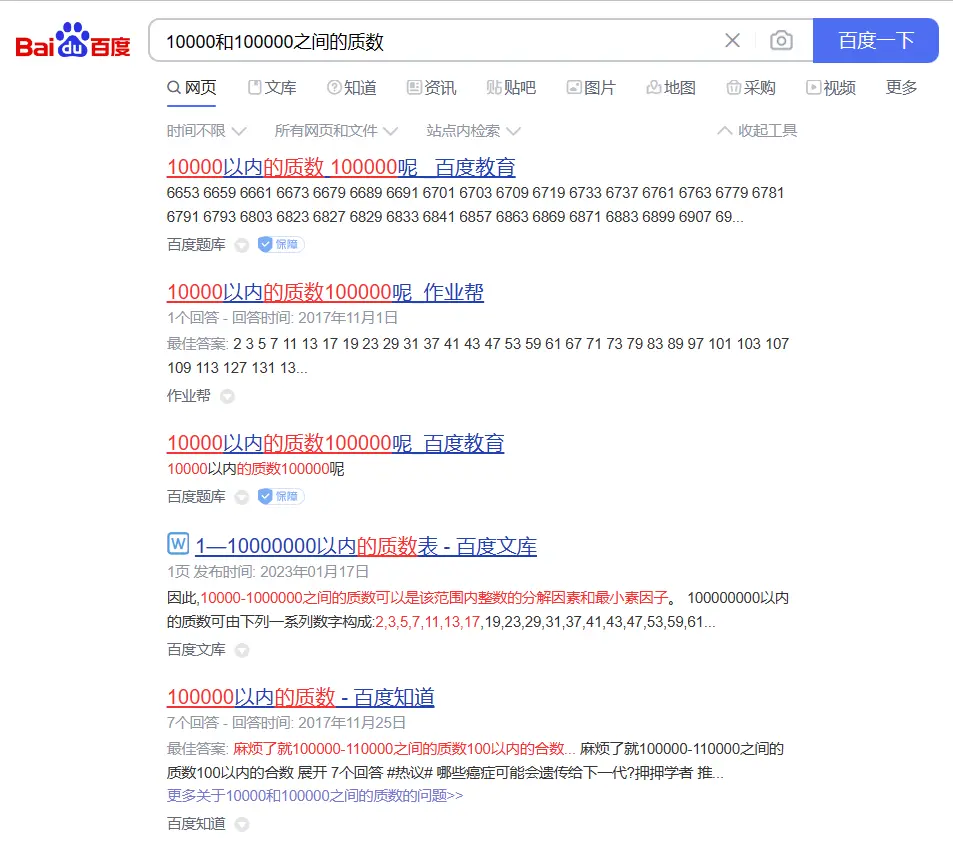
但这并不是因为百度搜索更厉害,而是因为有人类手动整理过这个相应的质数表,凭借生物的大脑和双手做过相关的工作,这才能被检索到。并且,最终得到答案也需要我对这些搜索结果做进一步的选择和加工。
接着我测试了一个难度不高但语言表述复杂一些的数学题:
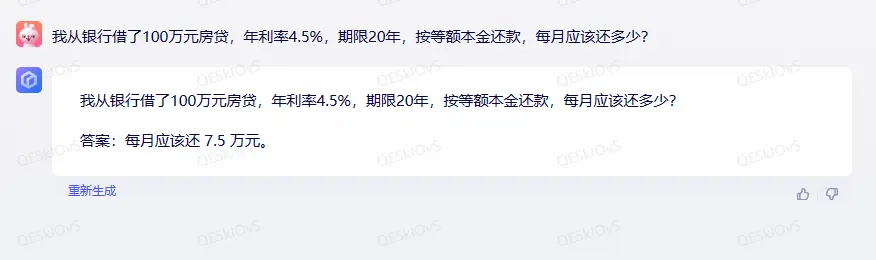
很可惜,文心一言又给出了错误的答案,而且错得很离谱。
如果我想用百度搜索来解决这个,虽然百度搜索不能直接回答,但它会提供由人类手动开发的计算工具:
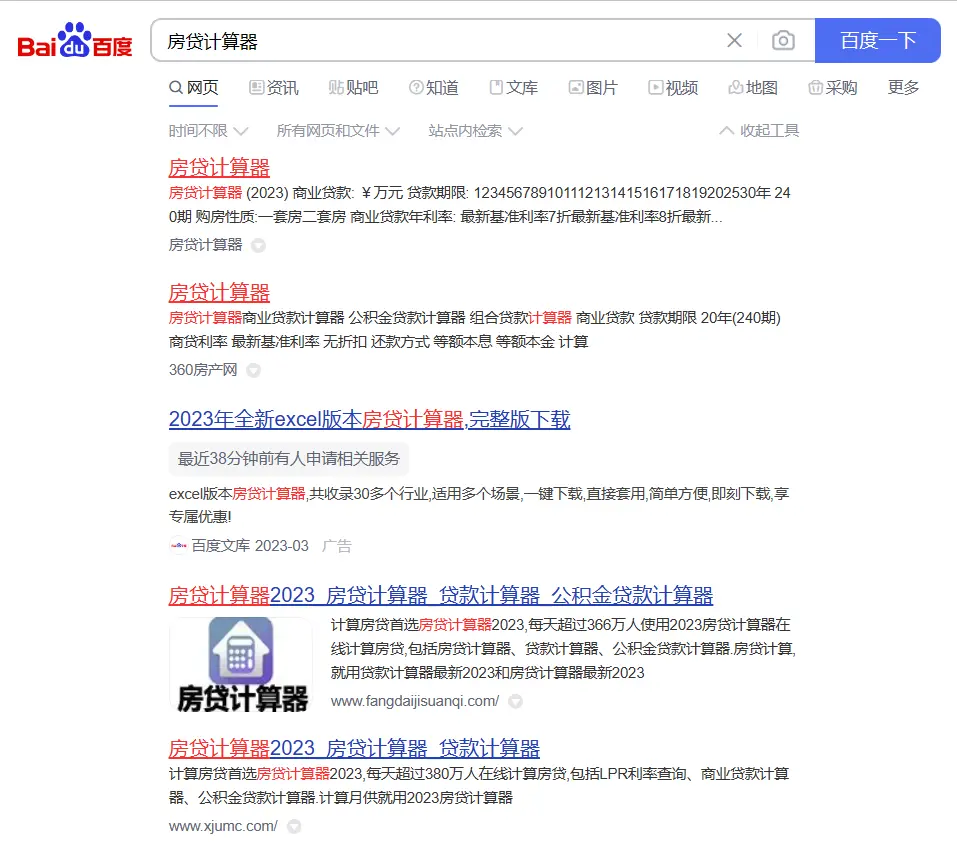
作为人类的一员,从这个场景也能隐约得到一些安慰,虽然机器的能力在飞速成长,但说到解决实际的问题,终究还是给人类留下了一些空间。
三、英语题
我先是测试了一个比较常规的句子翻译题:
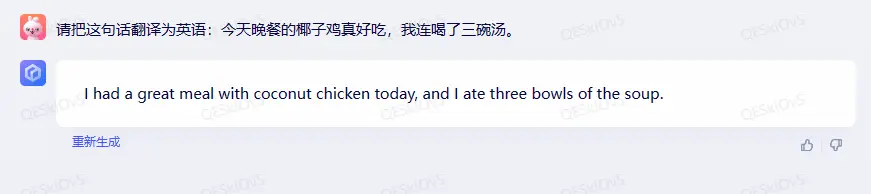
这个回答算是合格但并不优秀,我会给文心一言的表现打70分。
比起那些单独的翻译软件来说,这个得分并不突出,但人工智能的优势在于它可以直接理解人类的自然语言,它知道我要翻译的是后半部分,而不是把我输入的所有文字都翻译成英文。
对于人类来说,这是比“翻译器”更加友好的一种应用场景。
四、物理题
测试物理题的时候,我没有直接询问物理常识,而是增加了一点理解的难度,创造了一个真实世界并不存在的场景。

如果人工智能要准确回答这个问题,它需要做两步工作,一是找到重力常数的计算方法,二是找到我没有写出来但互联网上有现成答案的那些参数,比如地球和月球的质量、半径。
从上述结果可以看出来,文心一言只完成了第一步工作,找到了计算方法,但它还不会自己去找到相应参数来算出结果。
按我的理解,在未来很长一段时间内,人工智能能够给我们的帮助都将会局限在类似的水平,就是能帮助我们解决一部分的问题,提高一些效率,但无法给出准确可靠的最终结果。
机器还在成长,人类还有时间,问题就在于留给人类的时间还有多少……
五、化学题
这里我问了一个需要汇总的,带有一定开放性的问题,想知道人工智能会回答到什么程度。
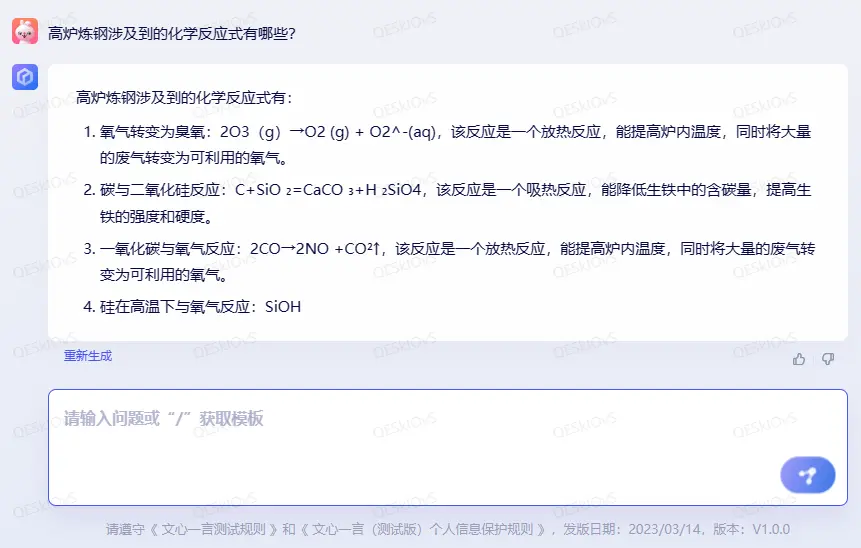
从文心一言反馈的结果来看,这个答案虽然不正确,但还是有可取之处的。
更重要的是,可以明显地看出来,文心一言回答这个问题不是从单一来源搬运答案,而是从不同来源获取信息后综合得到的答案。回答问题的结构也对人类非常友好,给出了相应化学式,还补充了重要的信息。
六、历史题
与自然学科不同,历史学科的问题经常带有一定的主观性,有时并没有唯一准确的答案,这样的问题能够测试人工智能对信息的选择偏好。
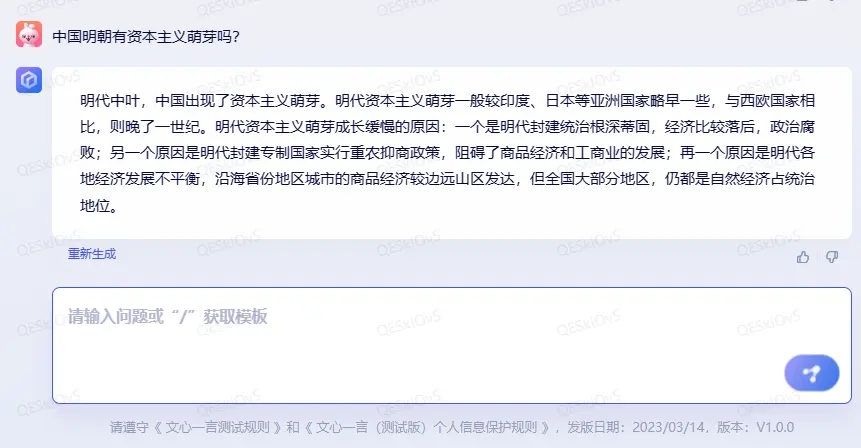
这个回答也是比较让我满意的,先是简洁地给出了肯定的答案,接着又补充了横向比较的信息和背后的原因。后面两部分我没问,但人工智能猜我会想知道,也一并把信息给了出来。
这是文心一言更像人而不是机器的特质,也是语言大模型最难的部分。从这个角度来说,文心一言还不够好用,但已经值得期待了。
从以上六个学科的问题来看,你会给文心一言的综合表现打多少分呢?





